Proyecto: Sitio web de intercambio de habilidades
Si tienes conocimiento, permite que otros enciendan sus velas en él.

Una reunión de intercambio de habilidades es un evento en el que personas con un interés compartido se reúnen y dan pequeñas presentaciones informales sobre cosas que saben. En una reunión de intercambio de habilidades de jardinería, alguien podría explicar cómo cultivar apio. O en un grupo de intercambio de habilidades de programación, podrías pasar y contarles a la gente sobre Node.js.
En este último capítulo del proyecto, nuestro objetivo es configurar un sitio web para gestionar las charlas impartidas en una reunión de intercambio de habilidades. Imagina un pequeño grupo de personas que se reúnen regularmente en la oficina de uno de los miembros para hablar sobre monociclos. El organizador anterior de las reuniones se mudó a otra ciudad y nadie se ofreció a asumir esta tarea. Queremos un sistema que permita a los participantes proponer y discutir charlas entre ellos, sin un organizador activo.
Al igual que en el capítulo anterior, parte del código en este capítulo está escrito para Node.js y es poco probable que funcione si se ejecuta directamente en la página HTML que estás viendo. El código completo del proyecto se puede descargar desde https://eloquentjavascript.net/code/skillsharing.zip.
Diseño
Este proyecto tiene una parte de servidor, escrita para Node.js, y una parte de cliente, escrita para el navegador. El servidor almacena los datos del sistema y los proporciona al cliente. También sirve los archivos que implementan el sistema del lado del cliente.
El servidor mantiene la lista de charlas propuestas para la próxima reunión, y el cliente muestra esta lista. Cada charla tiene un nombre de presentador, un título, un resumen y una matriz de comentarios asociados. El cliente permite a los usuarios proponer nuevas charlas (agregándolas a la lista), eliminar charlas y comentar en charlas existentes. Cada vez que el usuario realiza un cambio de este tipo, el cliente realiza una solicitud HTTP para informar al servidor al respecto.
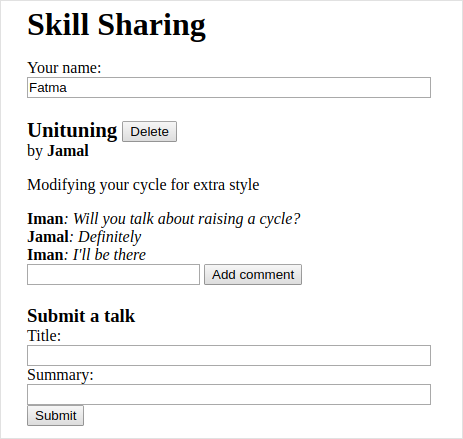
La aplicación se configurará para mostrar una vista en vivo de las charlas propuestas actuales y sus comentarios. Cada vez que alguien, en algún lugar, envíe una nueva charla o agregue un comentario, todas las personas que tengan la página abierta en sus navegadores deberían ver el cambio de inmediato. Esto plantea un desafío—no hay forma de que un servidor web abra una conexión a un cliente, ni hay una buena forma de saber qué clientes están viendo actualmente un sitio web dado.
Una solución común a este problema se llama long polling, que resulta ser una de las motivaciones del diseño de Node.
Long polling
Para poder notificar inmediatamente a un cliente que algo ha cambiado, necesitamos una conexión con ese cliente. Dado que los navegadores web tradicionalmente no aceptan conexiones y los clientes a menudo están detrás de routers que bloquearían tales conexiones de todos modos, no es práctico que sea el servidor quien inicie esta conexión.
Podemos hacer que el cliente abra la conexión y la mantenga activa para que el servidor pueda usarla para enviar información cuando sea necesario.
Sin embargo, una solicitud HTTP permite solo un flujo simple de información: el cliente envía una solicitud, el servidor responde una sola vez, y eso es todo. Existe una tecnología llamada WebSockets que permite abrir conexiones para el intercambio arbitrario de datos. Pero usarlas adecuadamente es algo complicado.
En este capítulo, utilizamos una técnica más sencilla—long polling—donde los clientes preguntan continuamente al servidor por nueva información mediante solicitudes HTTP regulares, y el servidor retiene su respuesta cuando no tiene nada nuevo que informar.
Mientras el cliente se asegure de tener una solicitud de sondeo abierta constantemente, recibirá información del servidor rápidamente cuando esté disponible. Por ejemplo, si Fatma tiene nuestra aplicación de intercambio de habilidades abierta en su navegador, ese navegador habrá solicitado actualizaciones y estará esperando una respuesta a esa solicitud. Cuando Iman envía una charla sobre “Extreme Downhill Unicycling”, el servidor notará que Fatma está esperando actualizaciones y enviará una respuesta que contiene la nueva charla a su solicitud pendiente. El navegador de Fatma recibirá los datos y actualizará la pantalla para mostrar la charla.
Para evitar que las conexiones se agoten por tiempo (se aborten debido a una falta de actividad), las técnicas de long polling suelen establecer un tiempo máximo para cada solicitud, tras el cual el servidor responderá de todos modos, aunque no tenga nada que informar. Entonces, el cliente puede iniciar una nueva solicitud. Reiniciar periódicamente la solicitud también hace que la técnica sea más robusta, permitiendo a los clientes recuperarse de fallos temporales de conexión o problemas de servidor.
Un servidor ocupado que utiliza long polling puede tener miles de solicitudes en espera, y por lo tanto conexiones TCP abiertas. Node, que facilita la gestión de muchas conexiones sin crear un hilo de control separado para cada una, es ideal para este tipo de sistema.
Interfaz HTTP
Antes de comenzar a diseñar el servidor o el cliente, pensemos en el punto donde se conectan: la interfaz HTTP a través de la cual se comunican.
Utilizaremos JSON como formato de nuestro cuerpo de solicitud y respuesta. Al igual que en el servidor de archivos del Capítulo 20, intentaremos hacer un buen uso de los métodos y cabeceras HTTP. La interfaz se centra en la ruta /talks. Las rutas que no comienzan con /talks se utilizarán para servir archivos estáticos—el código HTML y JavaScript para el sistema del lado del cliente.
Una solicitud GET a /talks devuelve un documento JSON como este:
[{"title": "Unituning",
"presenter": "Jamal",
"summary": "Modificando tu bicicleta para darle más estilo",
"comments": []}]
Crear una nueva charla se hace haciendo una solicitud PUT a una URL como /talks/Unituning, donde la parte después de la segunda barra es el título de la charla. El cuerpo de la solicitud PUT debe contener un objeto JSON que tenga propiedades presenter y summary.
Dado que los títulos de las charlas pueden contener espacios y otros caracteres que normalmente no aparecen en una URL, las cadenas de título deben ser codificadas con la función encodeURIComponent al construir una URL de ese tipo.
console.log("/talks/" + encodeURIComponent("Cómo hacer el caballito")); // → /talks/Cómo%20hacer%20el%20caballito
Una solicitud para crear una charla sobre hacer el caballito podría ser algo así:
PUT /talks/Cómo%20hacer%20el%20caballito HTTP/1.1 Content-Type: application/json Content-Length: 92 {"presenter": "Maureen", "summary": "Permanecer quieto sobre un monociclo"}
Estas URLs también admiten solicitudes GET para recuperar la representación JSON de una charla y solicitudes DELETE para eliminar una charla.
Agregar un comentario a una charla se hace con una solicitud POST a una URL como /, con un cuerpo JSON que tiene propiedades author y message.
POST /talks/Unituning/comments HTTP/1.1 Content-Type: application/json Content-Length: 72 {"author": "Iman", "message": "¿Vas a hablar sobre cómo levantar una bicicleta?"}
Para soportar encuestas prolongadas, las solicitudes GET a /talks pueden incluir encabezados adicionales que informen al servidor para retrasar la respuesta si no hay nueva información disponible. Usaremos un par de encabezados normalmente destinados a gestionar el almacenamiento en caché: ETag y If-None-Match.
Los servidores pueden incluir un encabezado ETag (“etiqueta de entidad”) en una respuesta. Su valor es una cadena que identifica la versión actual del recurso. Los clientes, al solicitar posteriormente ese recurso de nuevo, pueden hacer una solicitud condicional incluyendo un encabezado If-None-Match cuyo valor contenga esa misma cadena. Si el recurso no ha cambiado, el servidor responderá con el código de estado 304, que significa “no modificado”, indicando al cliente que su versión en caché sigue siendo actual. Cuando la etiqueta no coincide, el servidor responde como de costumbre.
Necesitamos algo como esto, donde el cliente puede decirle al servidor qué versión de la lista de charlas tiene, y el servidor responde solo cuando esa lista ha cambiado. Pero en lugar de devolver inmediatamente una respuesta 304, el servidor debería demorar la respuesta y devolverla solo cuando haya algo nuevo disponible o haya transcurrido una cantidad de tiempo determinada. Para distinguir las solicitudes de encuestas prolongadas de las solicitudes condicionales normales, les damos otro encabezado, Prefer: wait=90, que le indica al servidor que el cliente está dispuesto a esperar hasta 90 segundos por la respuesta.El servidor mantendrá un número de versión que actualiza cada vez que cambian las charlas y lo utilizará como valor ETag. Los clientes pueden hacer solicitudes como esta para ser notificados cuando las charlas cambien:
GET /talks HTTP/1.1 If-None-Match: "4" Prefer: wait=90 (pasa el tiempo) HTTP/1.1 200 OK Content-Type: application/json ETag: "5" Content-Length: 295 [....]
El protocolo descrito aquí no realiza ningún control de acceso. Cualquiera puede comentar, modificar charlas e incluso eliminarlas. (Dado que Internet está lleno de matones, poner un sistema en línea sin una protección adicional probablemente no terminaría bien).
El servidor
Comencemos construyendo la parte del programa del lado del servidor. El código en esta sección se ejecuta en Node.js.
Enrutamiento
Nuestro servidor utilizará createServer de Node para iniciar un servidor HTTP. En la función que maneja una nueva solicitud, debemos distinguir entre los diferentes tipos de solicitudes (como se determina por el método y la ruta) que soportamos. Esto se puede hacer con una larga cadena de declaraciones if, pero hay una manera más elegante.
Un enrutador es un componente que ayuda a despachar una solicitud a la función que puede manejarla. Puedes indicarle al enrutador, por ejemplo, que las solicitudes PUT con una ruta que coincida con la expresión regular / (/talks/ seguido de un título de charla) pueden ser manejadas por una función dada. Además, puede ayudar a extraer las partes significativas de la ruta (en este caso el título de la charla), envueltas en paréntesis en la expresión regular, y pasarlas a la función manejadora.
Hay varios paquetes de enrutadores buenos en NPM, pero aquí escribiremos uno nosotros mismos para ilustrar el principio.
Este es router.mjs, que luego importaremos desde nuestro módulo del servidor:
export class Router { constructor() { this.routes = []; } add(method, url, handler) { this.routes.push({method, url, handler}); } async resolve(request, context) { let {pathname} = new URL(request.url, "http://d"); for (let {method, url, handler} of this.routes) { let match = url.exec(pathname); if (!match || request.method != method) continue; let parts = match.slice(1).map(decodeURIComponent); return handler(context, ...parts, request); } } }
El módulo exporta la clase Router. Un objeto de enrutador te permite registrar manejadores para métodos específicos y patrones de URL con su método add. Cuando una solicitud se resuelve con el método resolve, el enrutador llama al manejador cuyo método y URL coinciden con la solicitud y devuelve su resultado.
Las funciones manejadoras se llaman con el valor context dado a resolve. Utilizaremos esto para darles acceso al estado de nuestro servidor. Además, reciben las cadenas coincidentes para cualquier grupo que hayan definido en su expresión regular, y el objeto de solicitud. Las cadenas deben ser decodificadas de la URL ya que la URL cruda puede contener códigos estilo %20.
Sirviendo archivos
Cuando una solicitud no coincide con ninguno de los tipos de solicitud definidos en nuestro enrutador, el servidor debe interpretarlo como una solicitud de un archivo en el directorio public. Sería posible usar el servidor de archivos definido en el Capítulo 20 para servir dichos archivos, pero ni necesitamos ni queremos admitir solicitudes PUT y DELETE en archivos, y nos gustaría tener funciones avanzadas como el soporte para almacenamiento en caché. Así que usemos en cambio un servidor de archivos estático sólido y bien probado de NPM.
Opté por serve-static. Este no es el único servidor de este tipo en NPM, pero funciona bien y se ajusta a nuestros propósitos. El paquete serve-static exporta una función que puede ser llamada con un directorio raíz para producir una función manipuladora de solicitudes. La función manipuladora acepta los argumentos request y response proporcionados por el servidor de "node:http", y un tercer argumento, una función que se llamará si ningún archivo coincide con la solicitud. Queremos que nuestro servidor primero compruebe las solicitudes que deberíamos manejar de manera especial, según lo definido en el enrutador, por lo que lo envolvemos en otra función.
import {createServer} from "node:http"; import serveStatic from "serve-static"; function notFound(request, response) { response.writeHead(404, "Not found"); response.end("<h1>Not found</h1>"); } class SkillShareServer { constructor(talks) { this.talks = talks; this.version = 0; this.waiting = []; let fileServer = serveStatic("./public"); this.server = createServer((request, response) => { serveFromRouter(this, request, response, () => { fileServer(request, response, () => notFound(request, response)); }); }); } start(port) { this.server.listen(port); } stop() { this.server.close(); } }
La función serveFromRouter tiene la misma interfaz que fileServer, tomando los argumentos (request, response, next). Esto nos permite “encadenar” varios manipuladores de solicitudes, permitiendo que cada uno maneje la solicitud o pase la responsabilidad de eso al siguiente manejador. El manejador final, notFound, simplemente responde con un error de “no encontrado”.
Nuestra función serveFromRouter utiliza una convención similar a la del servidor de archivos del capítulo anterior para las respuestas: los manejadores en el enrutador devuelven promesas que se resuelven en objetos que describen la respuesta.
import {Router} from "./router.mjs"; const router = new Router(); const defaultHeaders = {"Content-Type": "text/plain"}; async function serveFromRouter(server, request, response, next) { let resolved = await router.resolve(request, server) .catch(error => { if (error.status != null) return error; return {body: String(error), status: 500}; }); if (!resolved) return next(); let {body, status = 200, headers = defaultHeaders} = await resolved; response.writeHead(status, headers); response.end(body); }
Charlas como recursos
Las charlas que se han propuesto se almacenan en la propiedad talks del servidor, un objeto cuyas propiedades son los títulos de las charlas. Agregaremos algunos controladores a nuestro enrutador que expongan estos como recursos HTTP bajo /.
El controlador para las solicitudes que GET una sola charla debe buscar la charla y responder ya sea con los datos JSON de la charla o con una respuesta de error 404.
const talkPath = /^\/charlas\/([^\/]+)$/; router.add("GET", talkPath, async (server, title) => { if (Object.hasOwn(server.talks, title)) { return {body: JSON.stringify(server.talks[title]), headers: {"Content-Type": "application/json"}}; } else { return {status: 404, body: `No se encontró la charla '${title}'`}; } });
Eliminar una charla se hace eliminándola del objeto talks.
router.add("DELETE", talkPath, async (server, title) => { if (Object.hasOwn(server.talks, title)) { delete server.talks[title]; server.updated(); } return {status: 204}; });
El método updated, que definiremos más adelante, notifica a las solicitudes de espera larga sobre el cambio.
Un controlador que necesita leer cuerpos de solicitud es el controlador PUT, que se utiliza para crear nuevas charlas. Debe verificar si los datos que se le proporcionaron tienen propiedades presentador y resumen, que son cadenas de texto. Cualquier dato que provenga de fuera del sistema podría ser un sinsentido y no queremos corromper nuestro modelo de datos interno o fallar cuando lleguen solicitudes incorrectas.
Si los datos parecen válidos, el controlador almacena un objeto que representa la nueva charla en el objeto talks, posiblemente sobrescribiendo una charla existente con este título, y nuevamente llama a updated.
Para leer el cuerpo del flujo de solicitud, utilizaremos la función json de "node:stream/, que recopila los datos en el flujo y luego los analiza como JSON. Hay exportaciones similares llamadas text (para leer el contenido como una cadena) y buffer (para leerlo como datos binarios) en este paquete. Dado que json es un nombre genérico, la importación lo renombra a readJSON para evitar confusiones.
import {json as readJSON} from "node:stream/consumers" router.add("PUT", talkPath, async (server, title, request) => { let talk = await readJSON(request); if (!talk || typeof talk.presenter != "string" || typeof talk.summary != "string") { return {status: 400, body: "Datos de charla incorrectos"}; } server.talks[title] = { title, presenter: talk.presenter, summary: talk.summary, comments: [] }; server.updated(); return {status: 204}; }); ```Agregar un ((comentario)) a una ((charla)) funciona de manera similar. Usamos `readJSON` para obtener el contenido de la solicitud, validamos los datos resultantes y los almacenamos como un comentario cuando parecen válidos. ```{includeCode: ">code/skillsharing/skillsharing_server.mjs"} router.add("POST", /^\/talks\/([^\/]+)\/comments$/, async (server, title, request) => { let comment = await readJSON(request); if (!comment || typeof comment.author != "string" || typeof comment.message != "string") { return {status: 400, body: "Datos de comentario incorrectos"}; } else if (Object.hasOwn(server.talks, title)) { server.talks[title].comments.push(comment); server.updated(); return {status: 204}; } else { return {status: 404, body: `No se encontró la charla '${title}'`}; } });
Intentar agregar un comentario a una charla inexistente devuelve un error 404.
Soporte para larga espera
El aspecto más interesante del servidor es la parte que maneja la larga espera. Cuando llega una solicitud GET para /charlas, puede ser una solicitud regular o una solicitud de larga espera.
Habrá varios lugares en los que debamos enviar una matriz de charlas al cliente, por lo que primero definimos un método auxiliar que construya dicha matriz e incluya un encabezado ETag en la respuesta.
SkillShareServer.prototype.talkResponse = function() { let talks = Object.keys(this.talks) .map(title => this.talks[title]); return { body: JSON.stringify(talks), headers: {"Content-Type": "application/json", "ETag": `"${this.version}"`, "Cache-Control": "no-store"} }; };
El controlador en sí mismo necesita examinar los encabezados de la solicitud para ver si están presentes los encabezados If-None-Match y Prefer. Node almacena los encabezados, cuyos nombres se especifican como insensibles a mayúsculas y minúsculas, bajo sus nombres en minúsculas.
router.add("GET", /^\/talks$/, async (server, request) => { let tag = /"(.*)"/.exec(request.headers["if-none-match"]); let wait = /\bwait=(\d+)/.exec(request.headers["prefer"]); if (!tag || tag[1] != server.version) { return server.talkResponse(); } else if (!wait) { return {status: 304}; } else { return server.waitForChanges(Number(wait[1])); } });
Si no se proporcionó ninguna etiqueta o se proporcionó una etiqueta que no coincide con la versión actual del servidor, el controlador responde con la lista de charlas. Si la solicitud es condicional y las charlas no han cambiado, consultamos el encabezado Prefer para ver si debemos retrasar la respuesta o responder de inmediato.
Las funciones de devolución de llamada para solicitudes retardadas se almacenan en la matriz waiting del servidor para que puedan ser notificadas cuando ocurra algo. El método waitForChanges también establece inmediatamente un temporizador para responder con un estado 304 cuando la solicitud haya esperado el tiempo suficiente.
SkillShareServer.prototype.waitForChanges = function(time) { return new Promise(resolve => { this.waiting.push(resolve); setTimeout(() => { if (!this.waiting.includes(resolve)) return; this.waiting = this.waiting.filter(r => r != resolve); resolve({status: 304}); }, time * 1000); }); };
Registrar un cambio con updated incrementa la propiedad versión y despierta todas las solicitudes en espera.
SkillShareServer.prototype.updated = function() { this.version++; let response = this.talkResponse(); this.waiting.forEach(resolve => resolve(response)); this.waiting = []; };
Eso concluye el código del servidor. Si creamos una instancia de SkillShareServer y la iniciamos en el puerto 8000, el servidor HTTP resultante servirá archivos desde el subdirectorio public junto con una interfaz para manejar charlas bajo la URL /talks.
new SkillShareServer({}).start(8000);
El cliente
La parte del cliente del sitio web de intercambio de habilidades consiste en tres archivos: una pequeña página HTML, una hoja de estilos y un archivo JavaScript.
HTML
Es una convención ampliamente utilizada para servidores web intentar servir un archivo llamado index.html cuando se realiza una solicitud directamente a una ruta que corresponde a un directorio. El módulo de servidor de archivos que utilizamos, serve-static, soporta esta convención. Cuando se realiza una solicitud a la ruta /, el servidor busca el archivo ./ (./public siendo la raíz que le dimos) y devuelve ese archivo si se encuentra.
Por lo tanto, si queremos que una página aparezca cuando un navegador apunta a nuestro servidor, deberíamos colocarla en public/. Este es nuestro archivo de índice:
<meta charset="utf-8"> <title>Intercambio de habilidades</title> <link rel="stylesheet" href="skillsharing.css"> <h1>Intercambio de habilidades</h1> <script src="skillsharing_client.js"></script>
Define el título del documento e incluye una hoja de estilos, que define algunos estilos para, entre otras cosas, asegurarse de que haya algo de espacio entre las charlas. Luego agrega un encabezado en la parte superior de la página y carga el script que contiene la aplicación del cliente.
Acciones
El estado de la aplicación consiste en la lista de charlas y el nombre del usuario, y lo almacenaremos en un objeto {charlas, usuario}. No permitimos que la interfaz de usuario manipule directamente el estado ni envíe solicitudes HTTP. En cambio, puede emitir acciones que describen lo que el usuario está intentando hacer.
La función handleAction toma una acción de este tipo y la lleva a cabo. Debido a que nuestras actualizaciones de estado son tan simples, los cambios de estado se manejan en la misma función.
function handleAction(state, action) { if (action.type == "setUser") { localStorage.setItem("userName", action.user); return {...state, user: action.user}; } else if (action.type == "setTalks") { return {...state, talks: action.talks}; } else if (action.type == "newTalk") { fetchOK(talkURL(action.title), { method: "PUT", headers: {"Content-Type": "application/json"}, body: JSON.stringify({ presenter: state.user, summary: action.summary }) }).catch(reportError); } else if (action.type == "deleteTalk") { fetchOK(talkURL(action.talk), {method: "DELETE"}) .catch(reportError); } else if (action.type == "newComment") { fetchOK(talkURL(action.talk) + "/comments", { method: "POST", headers: {"Content-Type": "application/json"}, body: JSON.stringify({ author: state.user, message: action.message }) }).catch(reportError); } return state; }
Almacenaremos el nombre del usuario en localStorage para que pueda ser restaurado cuando se cargue la página.
Las acciones que necesitan involucrar al servidor realizan peticiones a la red, utilizando fetch, a la interfaz HTTP descrita anteriormente. Utilizamos una función de envoltura, fetchOK, que se asegura de que la promesa devuelta sea rechazada cuando el servidor devuelve un código de error.
function fetchOK(url, options) { return fetch(url, options).then(response => { if (response.status < 400) return response; else throw new Error(response.statusText); }); }
Esta función auxiliar se utiliza para construir una URL para una charla con un título dado.
function talkURL(title) { return "talks/" + encodeURIComponent(title); }
Cuando la petición falla, no queremos que nuestra página simplemente se quede ahí, sin hacer nada sin explicación. Así que definimos una función llamada reportError, que al menos muestra al usuario un cuadro de diálogo que le informa que algo salió mal.
function reportError(error) { alert(String(error)); }
Renderización de componentes
Utilizaremos un enfoque similar al que vimos en el Capítulo 19, dividiendo la aplicación en componentes. Pero dado que algunos de los componentes nunca necesitan actualizarse o siempre se redibujan por completo cuando se actualizan, definiremos aquellos no como clases, sino como funciones que devuelven directamente un nodo DOM. Por ejemplo, aquí hay un componente que muestra el campo donde el usuario puede ingresar su nombre:
function renderUserField(name, dispatch) { return elt("label", {}, "Tu nombre: ", elt("input", { type: "text", value: name, onchange(event) { dispatch({type: "setUser", user: event.target.value}); } })); }
La función elt utilizada para construir elementos DOM es la misma que usamos en el Capítulo 19.
Se utiliza una función similar para renderizar charlas, que incluyen una lista de comentarios y un formulario para agregar un nuevo comentario.
function renderTalk(talk, dispatch) { return elt( "section", {className: "talk"}, elt("h2", null, talk.title, " ", elt("button", { type: "button", onclick() { dispatch({type: "deleteTalk", talk: talk.title}); } }, "Eliminar")), elt("div", null, "por ", elt("strong", null, talk.presenter)), elt("p", null, talk.summary), ...talk.comments.map(renderComment), elt("form", { onsubmit(event) { event.preventDefault(); let form = event.target; dispatch({type: "newComment", talk: talk.title, message: form.elements.comment.value}); form.reset(); } }, elt("input", {type: "text", name: "comment"}), " ", elt("button", {type: "submit"}, "Añadir comentario"))); }
El controlador de evento "submit" llama a form.reset para limpiar el contenido del formulario después de crear una acción "newComment".
Cuando se crean piezas moderadamente complejas del DOM, este estilo de programación comienza a verse bastante desordenado. Para evitar esto, a menudo la gente utiliza un lenguaje de plantillas, que permite escribir la interfaz como un archivo HTML con algunos marcadores especiales para indicar dónde van los elementos dinámicos. O utilizan JSX, un dialecto de JavaScript no estándar que te permite escribir algo muy parecido a etiquetas HTML en tu programa como si fueran expresiones JavaScript. Ambos enfoques utilizan herramientas adicionales para preprocesar el código antes de que pueda ser ejecutado, lo cual evitaremos en este capítulo.
Los comentarios son simples de renderizar.
function renderComment(comment) { return elt("p", {className: "comment"}, elt("strong", null, comment.author), ": ", comment.message); }
Finalmente, el formulario que el usuario puede usar para crear una nueva charla se representa de la siguiente manera:
function renderTalkForm(dispatch) { let title = elt("input", {type: "text"}); let summary = elt("input", {type: "text"}); return elt("form", { onsubmit(event) { event.preventDefault(); dispatch({type: "newTalk", title: title.value, summary: summary.value}); event.target.reset(); } }, elt("h3", null, "Enviar una charla"), elt("label", null, "Título: ", title), elt("label", null, "Resumen: ", summary), elt("button", {type: "submit"}, "Enviar")); }
Sondeo
Para iniciar la aplicación necesitamos la lista actual de charlas. Dado que la carga inicial está estrechamente relacionada con el proceso de sondeo prolongado, el ETag de la carga debe ser utilizado al sondear, escribiremos una función que siga sondeando al servidor en busca de /charlas y llame a una función de devolución de llamada cuando un nuevo conjunto de charlas esté disponible.
async function pollTalks(update) { let tag = undefined; for (;;) { let response; try { response = await fetchOK("/charlas", { headers: tag && {"If-None-Match": tag, "Prefer": "wait=90"} }); } catch (e) { console.log("La solicitud falló: " + e); await new Promise(resolve => setTimeout(resolve, 500)); continue; } if (response.status == 304) continue; tag = response.headers.get("ETag"); update(await response.json()); } }
Esta es una función async para facilitar el bucle y la espera de la solicitud. Ejecuta un bucle infinito que, en cada iteración, recupera la lista de charlas, ya sea normalmente o, si esta no es la primera solicitud, con las cabeceras incluidas que la convierten en una solicitud de sondeo prolongado.
Cuando una solicitud falla, la función espera un momento y luego intenta nuevamente. De esta manera, si tu conexión de red se interrumpe por un tiempo y luego vuelve, la aplicación puede recuperarse y continuar actualizándose. La promesa resuelta a través de setTimeout es una forma de forzar a la función async a esperar.
Cuando el servidor devuelve una respuesta 304, eso significa que una solicitud de intercambio de larga duración expiró, por lo que la función debería comenzar inmediatamente la siguiente solicitud. Si la respuesta es un estado 200 normal, su cuerpo se lee como JSON y se pasa a la devolución de llamada, y el valor del encabezado ETag se almacena para la próxima iteración.
La aplicación
El siguiente componente une toda la interfaz de usuario:
class SkillShareApp { constructor(state, dispatch) { this.dispatch = dispatch; this.talkDOM = elt("div", {className: "talks"}); this.dom = elt("div", null, renderUserField(state.user, dispatch), this.talkDOM, renderTalkForm(dispatch)); this.syncState(state); } syncState(state) { if (state.talks != this.talks) { this.talkDOM.textContent = ""; for (let talk of state.talks) { this.talkDOM.appendChild( renderTalk(talk, this.dispatch)); } this.talks = state.talks; } } }
Cuando las charlas cambian, este componente las vuelve a dibujar todas. Esto es simple pero también derrochador. Hablaremos sobre eso en los ejercicios.
Podemos iniciar la aplicación de esta manera:
function runApp() { let user = localStorage.getItem("userName") || "Anon"; let state, app; function dispatch(action) { state = handleAction(state, action); app.syncState(state); } pollTalks(talks => { if (!app) { state = {user, talks}; app = new SkillShareApp(state, dispatch); document.body.appendChild(app.dom); } else { dispatch({type: "setTalks", talks}); } }).catch(reportError); } runApp();
Si ejecutas el servidor y abres dos ventanas del navegador para http://localhost:8000 una al lado de la otra, puedes ver que las acciones que realizas en una ventana son inmediatamente visibles en la otra.
Ejercicios
Los siguientes ejercicios implicarán modificar el sistema definido en este capítulo. Para trabajar en ellos, asegúrate de descargar primero el código (https://eloquentjavascript.net/code/skillsharing.zip), tener Node instalado (https://nodejs.org), e instalar la dependencia del proyecto con npm install.
Persistencia en disco
El servidor de intercambio de habilidades mantiene sus datos puramente en memoria. Esto significa que cuando se produce un fallo o se reinicia por cualquier motivo, se pierden todas las charlas y comentarios.
Extiende el servidor para que almacene los datos de las charlas en disco y vuelva a cargar automáticamente los datos cuando se reinicie. No te preocupes por la eficiencia, haz lo más simple que funcione.
Mostrar pistas...
La solución más simple que se me ocurre es codificar todo el objeto talks como JSON y volcarlo en un archivo con writeFile. Ya existe un método (updated) que se llama cada vez que cambian los datos del servidor. Se puede ampliar para escribir los nuevos datos en el disco.
Elige un nombre de archivo, por ejemplo ./talks.json. Cuando el servidor se inicie, puede intentar leer ese archivo con readFile, y si tiene éxito, el servidor puede usar el contenido del archivo como sus datos iniciales.
Restablecimiento del campo de comentarios
La remodelación completa de las charlas funciona bastante bien porque generalmente no se puede distinguir entre un nodo de DOM y su sustitución idéntica. Pero hay excepciones. Si empiezas a escribir algo en el campo de comentarios para una charla en una ventana del navegador y luego, en otra, añades un comentario a esa charla, el campo en la primera ventana se volverá a dibujar, eliminando tanto su contenido como su enfoque.
Cuando varias personas están añadiendo comentarios al mismo tiempo, esto podría resultar molesto. ¿Puedes idear una manera de resolverlo?
Mostrar pistas...
La mejor manera de hacerlo probablemente sea convertir el componente de la charla en un objeto, con un método syncState, para que se puedan actualizar para mostrar una versión modificada de la charla. Durante el funcionamiento normal, la única forma en que una charla puede cambiar es añadiendo más comentarios, por lo que el método syncState puede ser relativamente sencillo.
La parte difícil es que, cuando llega una lista modificada de charlas, tenemos que conciliar la lista existente de componentes de DOM con las charlas de la nueva lista: eliminar los componentes cuya charla fue eliminada y actualizar los componentes cuya charla cambió.
Para hacer esto, podría ser útil mantener una estructura de datos que almacene los componentes de las charlas bajo los títulos de las charlas para que puedas averiguar fácilmente si existe un componente para una charla dada. Luego puedes recorrer la nueva matriz de charlas y, para cada una de ellas, sincronizar un componente existente o crear uno nuevo. Para eliminar los componentes de charlas eliminadas, también tendrás que recorrer los componentes y comprobar si las charlas correspondientes aún existen.